
Pythonにはモジュールが豊富にあるのは良いのですがPython自体のバージョンや対応OSの違いによってパッケージのインストールの仕方に違いがあったりして面倒臭い所があります。
特に文章の形態素解析に使えるMecabというモジュールのWindows10の64Bit版のインストールは他のサイト様でも解説している所はありますが複雑です。
そこで今回はWindows10の64Bit版のインストールを記してみます。
64Bit版windows10でMecabをインストールする方法
MeCab 0.996 64bit versionのインストール
まずhttps://github.com/ikegami-yukino/mecab/releases/tag/v0.996のサイトへ行きます。
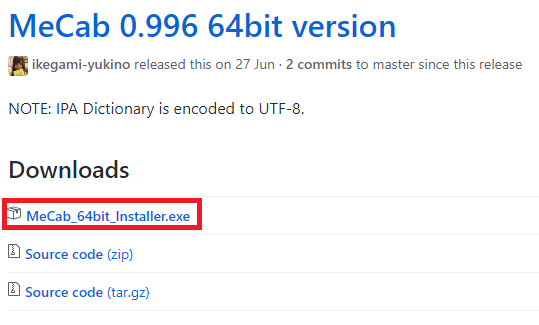 そしてWindows10の64Bit版ではDownloadsの項目のMeCab_64bit_Installer.exeというインストーラーをダウンロードします。
そしてWindows10の64Bit版ではDownloadsの項目のMeCab_64bit_Installer.exeというインストーラーをダウンロードします。
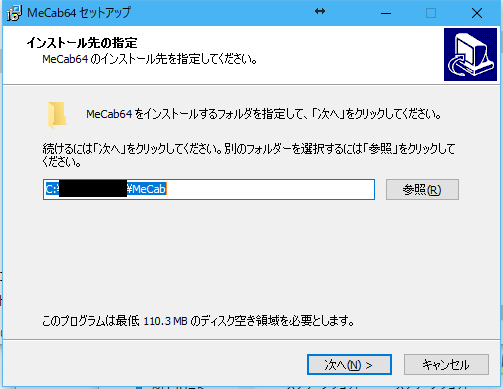 起動すると「MeCab64 セットアップ」のダイアログが表示されます。
起動すると「MeCab64 セットアップ」のダイアログが表示されます。
ここで参照ボタンを押せばMeCabを任意の場所にインストールする事もできますし、「次へ」と書かれたボタンを押せばインストールが開始されます。
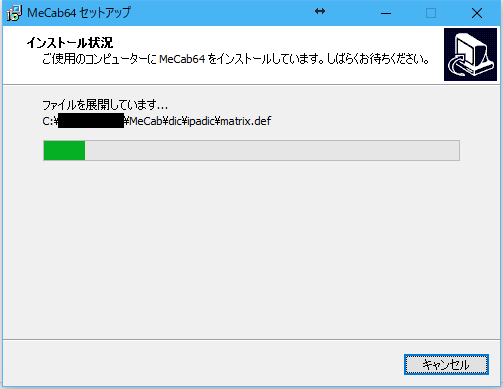 インストールが開始されると、この画面に切り替わりますので、暫く待ちます。
インストールが開始されると、この画面に切り替わりますので、暫く待ちます。
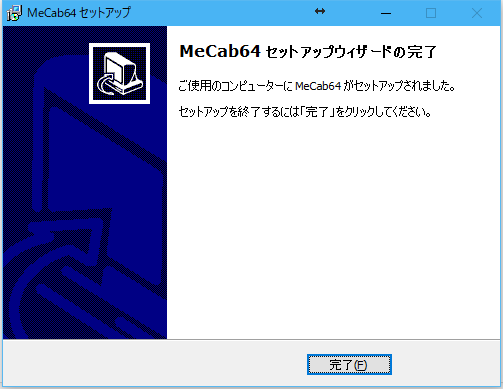 コピーが完了すればこのダイアログが表示されます。
コピーが完了すればこのダイアログが表示されます。
「完了」ボタンを押せばインストール完了です。
libmecab.libのコピー&ペースト
次にPythonがインストールされているフォルダにMeCab_64bit_Installer.exeでインストールしたlibmecab.libをコピー&ペーストします。
libmecab.libが入っているのは「MeCabをインストールした場所\MeCab\sdk」です。
これをペーストするべきPythonがインストールされているフォルダは「Pythonをインストールした場所\Lib\site-packages」となっています。
「Pythonをインストールした場所」のフォルダが解らない場合は「IDLE」を起動します。
そして上部メニューの「FILE」項目を展開させた中にある「OPEN」を選ぶとファイルを選択するダイアログが表示します。
このダイアログで最初に指定されているのが「Pythonをインストールした場所」です。
このフォルダの中の「Lib」の中の「site-packages」へlibmecab.libを貼り付けてください。
追記:libmecab.dllのコピー&ペースト
PythonがインストールされているフォルダにMeCab_64bit_Installer.exeでインストールしたlibmecab.dllもコピー&ペーストします。
libmecab.dllが入っているのは「MeCabをインストールした場所\MeCab\bin」です。
これをペーストするフォルダはlibmecab.libと同じ「Pythonをインストールした場所\Lib\site-packages」です。
mecab_python_windows-0.9.9.6-cp36-cp36m-win_amd64.whlのインストール
次にMecabというパッケージをpipでインストールします。
pipで利用する方法はpipでPythonのパッケージをインストールする方法を参考にしてください。
インストールするパッケージ名はmecab-python-windowsです。
ただし、ファイルをダウンロードしてからインストールする必要があります。
まずhttps://pypi.python.org/pypi/mecab-python-windowsへアクセスします。
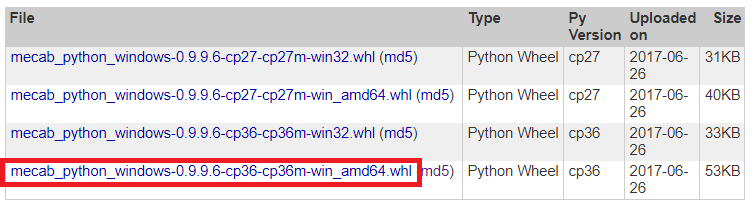 そしてmecab_python_windows-0.9.9.6-cp36-cp36m-win_amd64.whlをダウンロードします。
そしてmecab_python_windows-0.9.9.6-cp36-cp36m-win_amd64.whlをダウンロードします。
例えばこれをc:\に置いたとしたら
pip install "c:\mecab_python_windows-0.9.9.6-cp36-cp36m-win_amd64.whl"
とフルパスで書いた物を「”」で囲う、
もしくはコマンドプロンプトの方でCDコマンドを用いてパスを合わせ
pip install "mecab_python_windows-0.9.9.6-cp36-cp36m-win_amd64.whl"
と書きインストールします。
Mecabがインストールできたかの確認の為のサンプル
MeCabがインストール出来ているかを確認できるPythonのサンプルです。
import MeCab
mecab = MeCab.Tagger ("-Ochasen")
print(mecab.parse("MeCabを用いて文章を分割してみます。"))
このサンプルを実行する事ができればインストール成功です。
MeCab MeCab MeCab 名詞-一般 を ヲ を 助詞-格助詞-一般 用い モチイ 用いる 動詞-自立 一段 連用形 て テ て 助詞-接続助詞 文章 ブンショウ 文章 名詞-一般 を ヲ を 助詞-格助詞-一般 分割 ブンカツ 分割 名詞-サ変接続 し シ する 動詞-自立 サ変・スル 連用形 て テ て 助詞-接続助詞 み ミ みる 動詞-非自立 一段 連用形 ます マス ます 助動詞 特殊・マス 基本形 。 。 。 記号-句点 EOS
実行結果はこのように文章が形態素群に分割されて表示されます。
Mecabを文章自動生成プログラムでテスト
Mecabがインストール出来ていれば、ともっくすという方が公開している文章自動生成プログラム「TextGenerator」を使う事もできます。
サイトはPythonリハビリのために文章自動生成プログラムを作ってみたです。
TextGeneratorは実行する毎に内容の違うマルコフ連鎖を使った不思議な文章を作成します。
梶井基次郎の檸檬という文章がサンプルになっていますが、もっと珍奇な文を入れれば、昔よくあった”名詞や動詞をランダムで入れ替えて出力するミニゲーム”のパワーアップ版としてなかなか楽しめるかと思います。
ただし、このコードはPythonのバージョン2用に書かれた物なので、Pythonのバージョン3で動かすには、ちょっとだけ変更する必要があります。
以下、Python3用への変更例です。
PrepareChain.py
# -*- coding: utf-8 -*-
"""
与えられた文書からマルコフ連鎖のためのチェーン(連鎖)を作成して、DBに保存するファイル
"""
import unittest
import re
import MeCab
import sqlite3
from collections import defaultdict
class PrepareChain(object):
"""
チェーンを作成してDBに保存するクラス
"""
BEGIN = "__BEGIN_SENTENCE__"
END = "__END_SENTENCE__"
DB_PATH = "chain.db"
DB_SCHEMA_PATH = "schema.sql"
def __init__(self, text):
"""
初期化メソッド
@param text チェーンを生成するための文章
"""
#if isinstance(text, str):
# text = text.decode("utf-8")
self.text = text
# 形態素解析用タガー
self.tagger = MeCab.Tagger('-Ochasen')
def make_triplet_freqs(self):
"""
形態素解析から3つ組の出現回数まで
@return 3つ組とその出現回数の辞書 key: 3つ組(タプル) val: 出現回数
"""
# 長い文章をセンテンス毎に分割
sentences = self._divide(self.text)
# 3つ組の出現回数
triplet_freqs = defaultdict(int)
# センテンス毎に3つ組にする
for sentence in sentences:
# 形態素解析
morphemes = self._morphological_analysis(sentence)
# 3つ組をつくる
triplets = self._make_triplet(morphemes)
# 出現回数を加算
for (triplet, n) in triplets.items():
triplet_freqs[triplet] += n
return triplet_freqs
def _divide(self, text):
"""
「。」や改行などで区切られた長い文章を一文ずつに分ける
@param text 分割前の文章
@return 一文ずつの配列
"""
# 改行文字以外の分割文字(正規表現表記)
delimiter = "。|.|\."
# 全ての分割文字を改行文字に置換(splitしたときに「。」などの情報を無くさないため)
text = re.sub(r"({0})".format(delimiter), r"\1\n", text)
# 改行文字で分割
sentences = text.splitlines()
# 前後の空白文字を削除
sentences = [sentence.strip() for sentence in sentences]
return sentences
def _morphological_analysis(self, sentence):
"""
一文を形態素解析する
@param sentence 一文
@return 形態素で分割された配列
"""
morphemes = []
#sentence = sentence.encode("utf-8")
node = self.tagger.parseToNode(sentence)
while node:
if node.posid != 0:
#morpheme = node.surface.decode("utf-8")
morpheme = node.surface
morphemes.append(morpheme)
node = node.next
return morphemes
def _make_triplet(self, morphemes):
"""
形態素解析で分割された配列を、形態素毎に3つ組にしてその出現回数を数える
@param morphemes 形態素配列
@return 3つ組とその出現回数の辞書 key: 3つ組(タプル) val: 出現回数
"""
# 3つ組をつくれない場合は終える
if len(morphemes) < 3:
return {}
# 出現回数の辞書
triplet_freqs = defaultdict(int)
# 繰り返し
for i in range(len(morphemes)-2):
triplet = tuple(morphemes[i:i+3])
triplet_freqs[triplet] += 1
# beginを追加
triplet = (PrepareChain.BEGIN, morphemes[0], morphemes[1])
triplet_freqs[triplet] = 1
# endを追加
triplet = (morphemes[-2], morphemes[-1], PrepareChain.END)
triplet_freqs[triplet] = 1
return triplet_freqs
def save(self, triplet_freqs, init=False):
"""
3つ組毎に出現回数をDBに保存
@param triplet_freqs 3つ組とその出現回数の辞書 key: 3つ組(タプル) val: 出現回数
"""
# DBオープン
con = sqlite3.connect(PrepareChain.DB_PATH)
# 初期化から始める場合
if init:
# DBの初期化
with open(PrepareChain.DB_SCHEMA_PATH, "r") as f:
schema = f.read()
con.executescript(schema)
# データ整形
datas = [(triplet[0], triplet[1], triplet[2], freq) for (triplet, freq) in triplet_freqs.items()]
# データ挿入
p_statement = "insert into chain_freqs (prefix1, prefix2, suffix, freq) values (?, ?, ?, ?)"
con.executemany(p_statement, datas)
# コミットしてクローズ
con.commit()
con.close()
def show(self, triplet_freqs):
"""
3つ組毎の出現回数を出力する
@param triplet_freqs 3つ組とその出現回数の辞書 key: 3つ組(タプル) val: 出現回数
"""
for triplet in triplet_freqs:
print("|".join(triplet), "\t", triplet_freqs[triplet])
#------
#以下省略
※class TestFunctions(unittest.TestCase):というテスト用クラス以降は変更する必要がないので省略しています。
GenerateText.py
# -*- coding: utf-8 -*-
u"""
マルコフ連鎖を用いて適当な文章を自動生成するファイル
"""
import os.path
import sqlite3
import random
from PrepareChain import PrepareChain
class GenerateText(object):
u"""
文章生成用クラス
"""
def __init__(self, n=5):
u"""
初期化メソッド
@param n いくつの文章を生成するか
"""
self.n = n
def generate(self):
u"""
実際に生成する
@return 生成された文章
"""
# DBが存在しないときは例外をあげる
if not os.path.exists(PrepareChain.DB_PATH):
raise IOError(u"DBファイルが存在しません")
# DBオープン
con = sqlite3.connect(PrepareChain.DB_PATH)
con.row_factory = sqlite3.Row
# 最終的にできる文章
generated_text = u""
# 指定の数だけ作成する
for i in range(self.n):
text = self._generate_sentence(con)
generated_text += text
# DBクローズ
con.close()
return generated_text
def _generate_sentence(self, con):
u"""
ランダムに一文を生成する
@param con DBコネクション
@return 生成された1つの文章
"""
# 生成文章のリスト
morphemes = []
# はじまりを取得
first_triplet = self._get_first_triplet(con)
morphemes.append(first_triplet[1])
morphemes.append(first_triplet[2])
# 文章を紡いでいく
while morphemes[-1] != PrepareChain.END:
prefix1 = morphemes[-2]
prefix2 = morphemes[-1]
triplet = self._get_triplet(con, prefix1, prefix2)
morphemes.append(triplet[2])
# 連結
result = "".join(morphemes[:-1])
return result
def _get_chain_from_DB(self, con, prefixes):
u"""
チェーンの情報をDBから取得する
@param con DBコネクション
@param prefixes チェーンを取得するprefixの条件 tupleかlist
@return チェーンの情報の配列
"""
# ベースとなるSQL
sql = u"select prefix1, prefix2, suffix, freq from chain_freqs where prefix1 = ?"
# prefixが2つなら条件に加える
if len(prefixes) == 2:
sql += u" and prefix2 = ?"
# 結果
result = []
# DBから取得
cursor = con.execute(sql, prefixes)
for row in cursor:
result.append(dict(row))
return result
def _get_first_triplet(self, con):
u"""
文章のはじまりの3つ組をランダムに取得する
@param con DBコネクション
@return 文章のはじまりの3つ組のタプル
"""
# BEGINをprefix1としてチェーンを取得
prefixes = (PrepareChain.BEGIN,)
# チェーン情報を取得
chains = self._get_chain_from_DB(con, prefixes)
# 取得したチェーンから、確率的に1つ選ぶ
triplet = self._get_probable_triplet(chains)
return (triplet["prefix1"], triplet["prefix2"], triplet["suffix"])
def _get_triplet(self, con, prefix1, prefix2):
u"""
prefix1とprefix2からsuffixをランダムに取得する
@param con DBコネクション
@param prefix1 1つ目のprefix
@param prefix2 2つ目のprefix
@return 3つ組のタプル
"""
# BEGINをprefix1としてチェーンを取得
prefixes = (prefix1, prefix2)
# チェーン情報を取得
chains = self._get_chain_from_DB(con, prefixes)
# 取得したチェーンから、確率的に1つ選ぶ
triplet = self._get_probable_triplet(chains)
return (triplet["prefix1"], triplet["prefix2"], triplet["suffix"])
def _get_probable_triplet(self, chains):
u"""
チェーンの配列の中から確率的に1つを返す
@param chains チェーンの配列
@return 確率的に選んだ3つ組
"""
# 確率配列
probability = []
# 確率に合うように、インデックスを入れる
for (index, chain) in enumerate(chains):
for j in range(chain["freq"]):
probability.append(index)
# ランダムに1つを選ぶ
chain_index = random.choice(probability)
return chains[chain_index]
if __name__ == '__main__':
generator = GenerateText()
print(generator.generate())
Python2はprintが()で囲うようになっていなかったりxrangeという物があったりとPython3とは結構違います。
1個ずつ置き換えるのが面倒な場合にコピー&ペーストしてください。